01
 豆包对中国语境的理解最好,语料最丰富
豆包对中国语境的理解最好,语料最丰富
和豆包聊天——确定研究范围
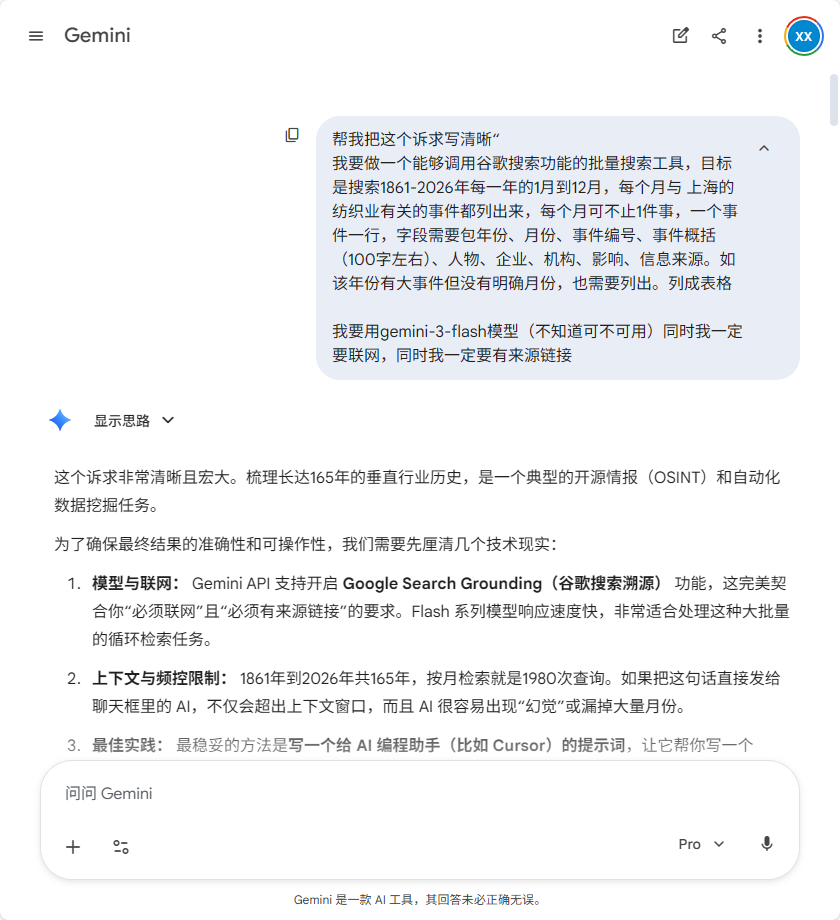
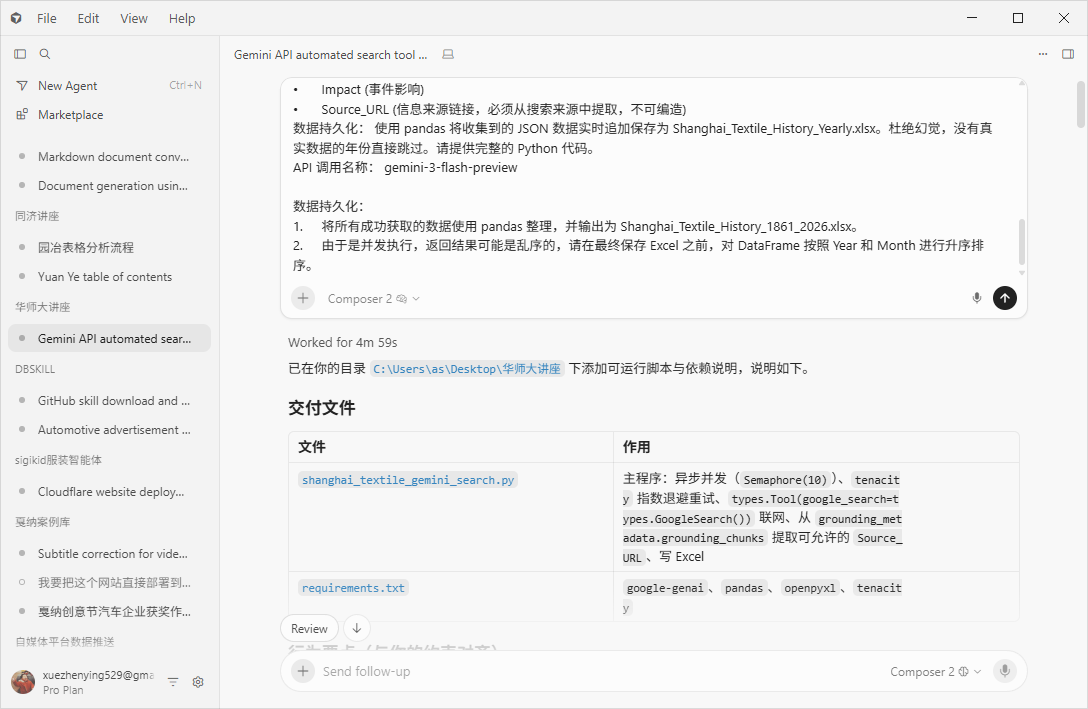
没有明确研究计划,随意聊。「上海纺织业是怎么发展起来的?」「近代化从什么时候开始的?」「经历过哪些大的阶段?」
发现信息量远比想象大,且非常分散——从 1861 年到现在,每一个阶段都有大量人物、事件、空间变化。于是决定:165 年全覆盖,不提前预设哪个阶段重要。
这一步的两层意义
① 建立基础认知——之前只知道「纺织业是上海的顶梁柱」和「老厂房改造」。
② 搞清楚后面数据应该提取哪些字段——时间、事件、人物、地点、机构、影响、数据来源。
② 搞清楚后面数据应该提取哪些字段——时间、事件、人物、地点、机构、影响、数据来源。